This post describes technology building blocks to enable digital transformation at Utah Valley University, but the principles and concepts are universal. Utah Valley University is digitally transforming. The faculty and staff are excited about the possibilities and are envisioning a better future for our students. Students should expect our transformation to yield richer experiences, enhanced learning activities, increased skill acquisition, and a less burdensome path to completion and success. Our faculty and staff should experience less administrative burden allowing them to provide exceptional care, exceptional accountability, and exceptional results to our students and one another.
To facilitate digital transformation, the Office of Information Technology (OIT) and Academic and Student Digital Services (ASDS) must also transform. They must provide reliable and easy-to-use technology solutions that faculty and staff can use to enhance their interactions with others and improve the products and services they deliver. OIT and ASDS must adapt, modernize, provide existing products and services at a reduced cost, and provide new products and services with exceptional customer service.

In general, products and services should be available via self-service, 24 by 7, and ample support to make technology consumers successful, satisfied, and even delighted. The remainder of this post describes architectures, principles, and philosophies intended to make these necessary changes and the dream described above possible.
Application Programming Interfaces
Application programming interfaces (APIs) make it easier for others to interact with applications, create and use alternative user interfaces, and use the available services for alternative and even unexpected purposes. When acquiring or developing an application, it must have an API, and preferably a RESTful one. Data, services, and processes needed to build an application are used to create an API. The resulting API is then consumed to deliver a user experience. Mashup Corporation by Andy Mulholland et al. is a short fictional read that illustrates these concepts and the enabling power of APIs.
To make them most valuable, APIs must be exposed and consumed through API management tools. APIs should be more than simple JSON-based CRUD interfaces; APIs should expose appropriate business logic so that API consumers cannot violate required business processes. Enforcing this principle allows others to build delightful user experiences without institutional concern about policy, practice, or process compliance.
Domain-Driven Design
Everyone should read at least the first two chapters of the book Implementing Domain-Driven Design by Vaughn Vernon! Here is my super-short summary of domain-driven design (DDD) and those chapters — bring domain experts and developers together to create a ubiquitous language embedded in the application code itself. In addition, define or determine bounded contexts wherein this language is valid. This exercise helps software developers genuinely understand the business processes they are being asked to automate. It also helps the business participants understand the code being written and allows them to question decisions, test assumptions, and find bugs before deployment. This collaborative group of business leaders and developers is “the team”; success or failure is in their hands.
Microservices
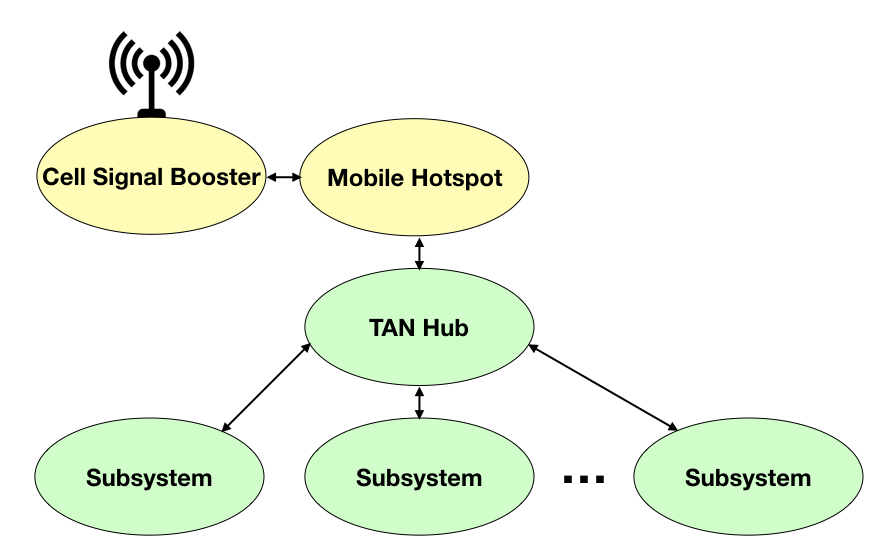
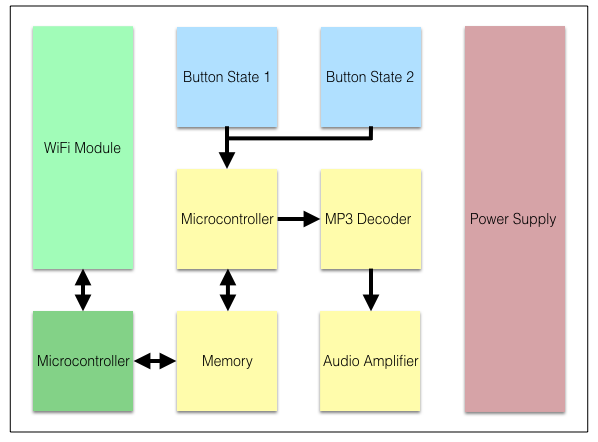
Microservices are an architectural style that will be used at UVU to create larger systems. Systems built using microservices are loosely coupled; I would even go as far as saying they are highly decoupled, implement a single business capability, have well-defined interfaces, and communicate using only these interfaces. The size of a microservice is governed by the associated bounded context, go, and read the DDD book! At UVU, an essential part of a microservices’ interface is its ability to raise events. Go figure out why.
Event-Driven Architecture (EDA)
Systems that poll are inefficient! Build systems that raise events so other systems don’t have to waste time and resources. You can keep asking me if you must do this, but you can be assured that when I change my mind, I’ll let you know. If you didn’t find the humor in the last sentence, then reread the links.
Application Acquisition
When we purchase applications, we should give preference and a strong preference to those running in the cloud. When we build services or applications, they should use the most abstract service offerings that make sense. In other words, we should not instantiate servers and consume storage and then build queues, notification services, etc. We should instead use services such as queues, notification systems, serverless functions, etc.
DevOps
DevOps is a culture and practice that we hope will result in rapid development, testing, and software deployment. We also hope this increases accountability by allowing those who develop an application to be responsible for running and supporting it. Nothing motivates a developer to fix a bug more than to wake them to fix it repeatedly. Teams, DDD teams, are in charge and responsible for the functionality, performance, and reliability of “their” products.
If those in the hardware world think you’re off the hook, think again. Software is eating the world. The days of interacting with network switches, routers, firewalls, servers, storage appliances, AV equipment, etc., are over. Learn to program, learn to configure hardware devices using programs, remember to use DevOps principles to configure, test, and deploy hardware platforms as rapidly as “other” developers – that’s right, you just became developers!
Where to Compute
We built data centers and populated them with servers, storage systems, and network components in the past. As CPU performance increased, computers became more able to run multiple applications, but stability due to unintentional application interaction made this approach intolerable.
We found ourselves with many underutilized servers running single applications to maintain reliability. Along came server virtualization enabling us to instantiate multiple virtual servers on each physical server. Over the past several years, the number of physical servers has diminished considerably.
Well, we’re in the middle of another paradigm shift. We are continuing our journey that will result in our compute and storage being somewhere else. Acquired applications will also run in the “cloud.” in either case, they will not be housed here.
Networks
Unlike server and storage, I believe we will have a wired and wireless network on campus for the foreseeable future. However, the way we deploy, configure, and maintain these networks will change drastically. Remember, software is eating the world, and networking is not an exception to the rule. Network components will be physically installed in some generic way and then configured remotely via software. In a DevOps fashion, when a problem occurs, you’ll figure out what went wrong in the configuration script, you’ll repair the script, you’ll test the script, and you’ll redeploy.
Final Thoughts – For Now!
We have a great team! Let’s pursue all this FUN with great enthusiasm. Let us share our best thinking with others: share code on GitHub, answer questions on StackOverflow, blog about your experiences, publish papers, present at conferences, participate in panel discussions. In short, learn, teach one another, and teach the world!